import pandas as pd
import numpy as np
from IPython.display import Audio, FileLink, display
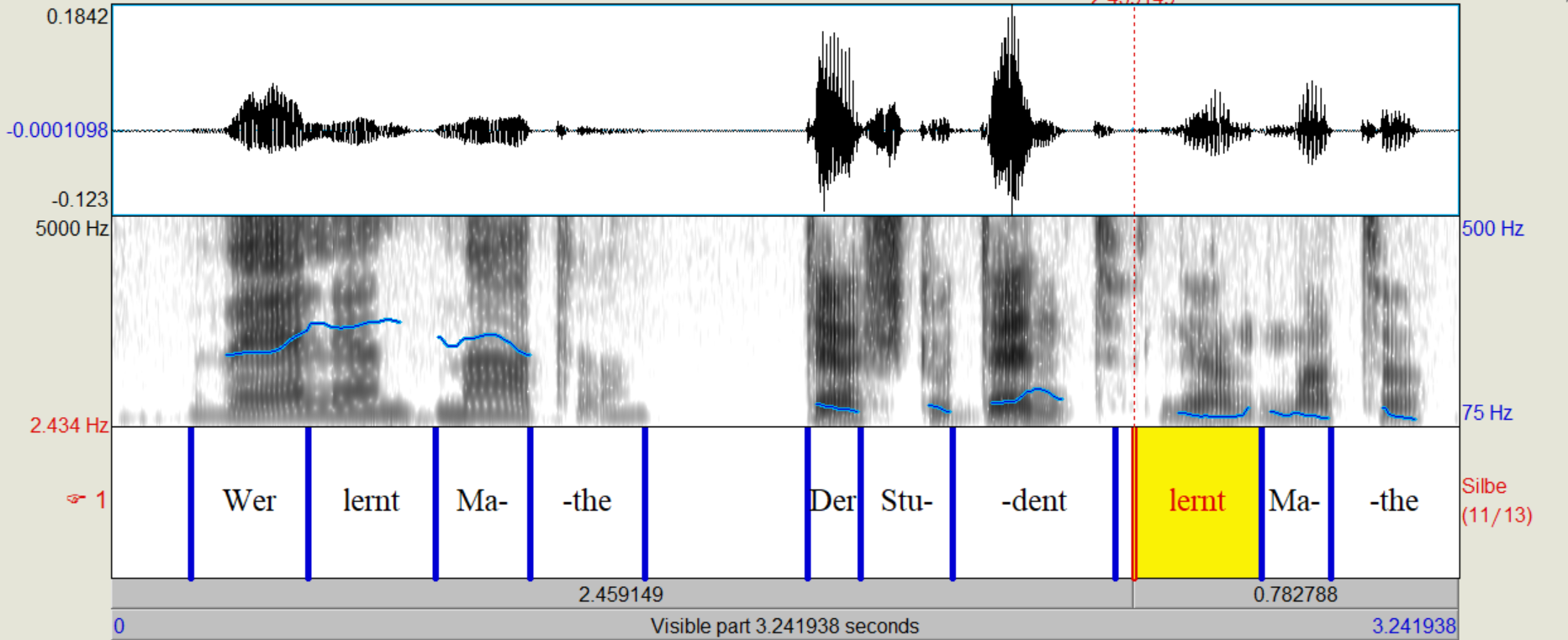
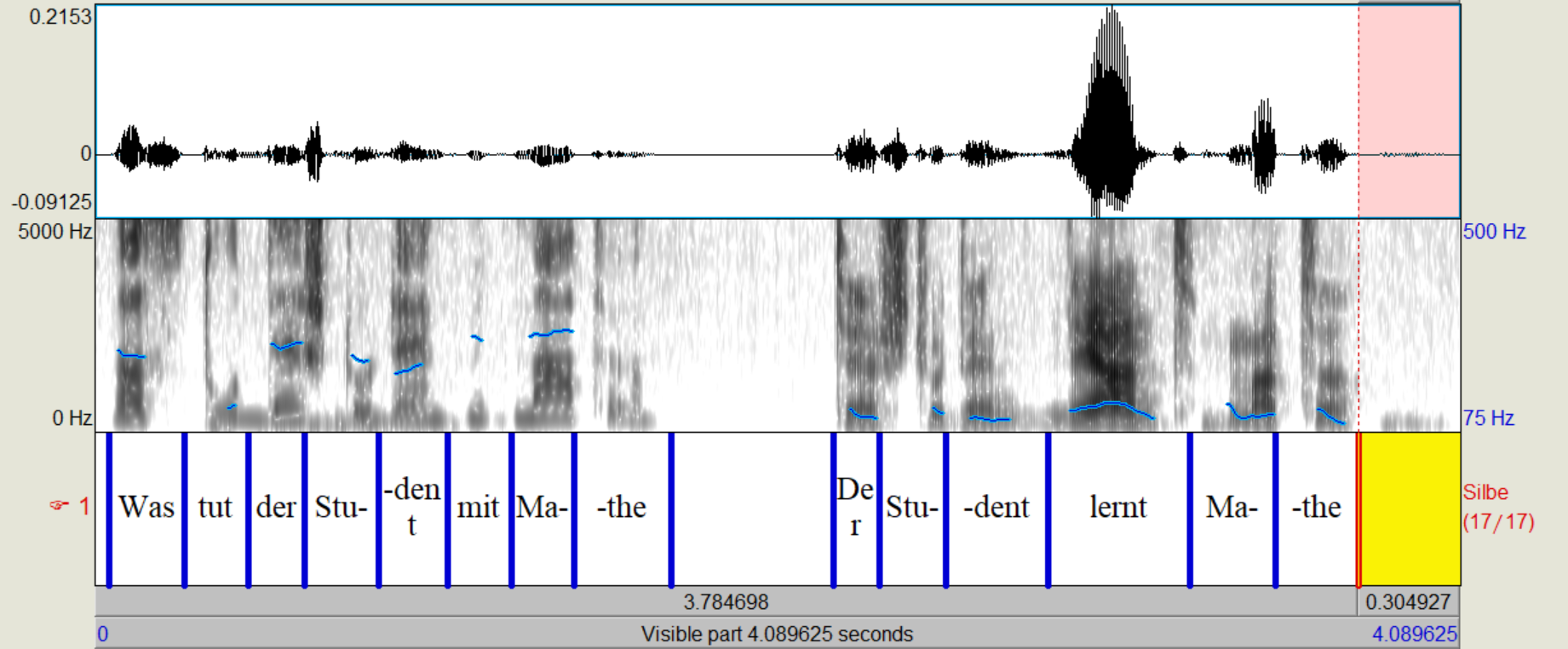
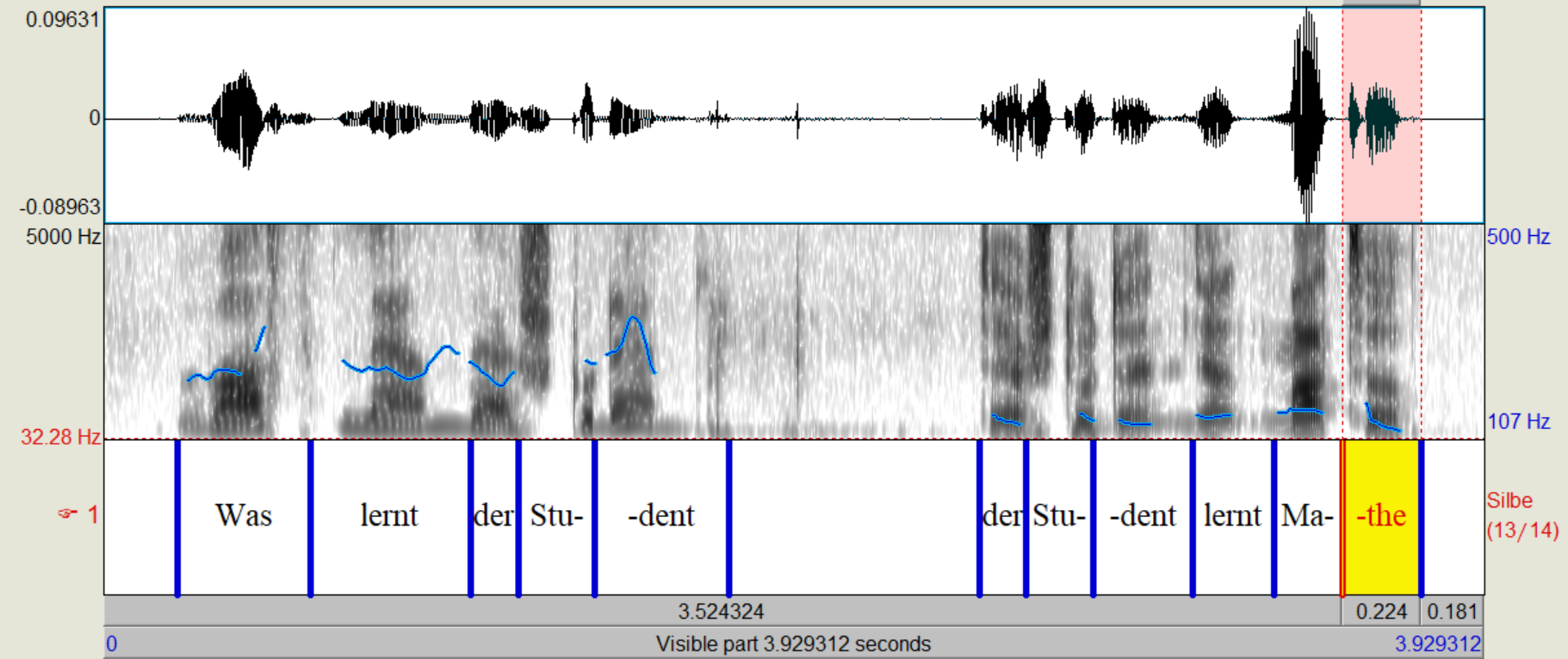
Der Student lernt Mathe.
Audio('sound/1.wav')
Audio('sound/1_monoton.wav')
silben = ["Der", "Stu", "dent", "lernt", "Ma", "the"]
silbendauer = [0.127, 0.221, 0.391, 0.306, 0.167, 0.31]
f0 = [113.2, 114.6, 150.4, 95.87, 102.6, 98.63]
intensity = [66.1, 57.0, 85.9, 56.1, 58.2, 54.34]
df_1 = pd.DataFrame({"Silbe": silben, "Silbendauer(ms)": silbendauer, "Grundfrequenz": f0, "Intensitaet(dB)": intensity})
df_1 = df_1.set_index("Silbe")
df_1["Silbendauer(%)"] = df_1["Silbendauer(ms)"] / df_1["Silbendauer(ms)"].sum() *100
df_1
| Silbendauer(ms) | Grundfrequenz | Intensitaet(dB) | Silbendauer(%) | |
|---|---|---|---|---|
| Silbe | ||||
| Der | 0.127 | 113.20 | 66.10 | 8.344284 |
| Stu | 0.221 | 114.60 | 57.00 | 14.520368 |
| dent | 0.391 | 150.40 | 85.90 | 25.689882 |
| lernt | 0.306 | 95.87 | 56.10 | 20.105125 |
| Ma | 0.167 | 102.60 | 58.20 | 10.972405 |
| the | 0.310 | 98.63 | 54.34 | 20.367937 |
Audio('sound/2.wav')
Audio('sound/2_monoton.wav')
silbendauer = [0.14, 0.198, 0.307, 0.422, 0.258, 0.248]
f0 = [105.5, np.nan, 110.2, 135.4, 132.8, 99.15]
intensity = [53.4, 53.4, 52.1, 66.1, 59.7, 53.2]
df_2 = pd.DataFrame({"Silbe": silben, "Silbendauer(ms)": silbendauer, "Grundfrequenz": f0, "Intensitaet(dB)": intensity})
df_2 = df_2.set_index("Silbe")
df_2["Silbendauer(%)"] = df_2["Silbendauer(ms)"] / df_2["Silbendauer(ms)"].sum() *100
df_2
| Silbendauer(ms) | Grundfrequenz | Intensitaet(dB) | Silbendauer(%) | |
|---|---|---|---|---|
| Silbe | ||||
| Der | 0.140 | 105.50 | 53.4 | 8.900191 |
| Stu | 0.198 | NaN | 53.4 | 12.587413 |
| dent | 0.307 | 110.20 | 52.1 | 19.516847 |
| lernt | 0.422 | 135.40 | 66.1 | 26.827718 |
| Ma | 0.258 | 132.80 | 59.7 | 16.401780 |
| the | 0.248 | 99.15 | 53.2 | 15.766052 |
Audio('sound/3.wav')
Audio('sound/3_monoton.wav')
silbendauer = [0.132, 0.191, 0.282, 0.231, 0.194, 0.224]
f0 = [111.9, 121.4, 105.1, 120, 132.8, 106]
intensity = [54.81, 54.37, 51.42, 52.28, 63.17, 56.69]
df_3 = pd.DataFrame({"Silbe": silben, "Silbendauer(ms)": silbendauer, "Grundfrequenz": f0, "Intensitaet(dB)": intensity})
df_3 = df_3.set_index("Silbe")
df_3["Silbendauer(%)"] = df_3["Silbendauer(ms)"] / df_3["Silbendauer(ms)"].sum() *100
df_3
| Silbendauer(ms) | Grundfrequenz | Intensitaet(dB) | Silbendauer(%) | |
|---|---|---|---|---|
| Silbe | ||||
| Der | 0.132 | 111.9 | 54.81 | 10.526316 |
| Stu | 0.191 | 121.4 | 54.37 | 15.231260 |
| dent | 0.282 | 105.1 | 51.42 | 22.488038 |
| lernt | 0.231 | 120.0 | 52.28 | 18.421053 |
| Ma | 0.194 | 132.8 | 63.17 | 15.470494 |
| the | 0.224 | 106.0 | 56.69 | 17.862839 |
Audio('sound/4.wav')
Audio('sound/4_monoton.wav')
silbendauer = [0.116, 0.153, 0.269, 0.181, 0.174, 0.225]
f0 = [106, np.nan, 109, 118.1, 156.3, 99.34]
intensity = [54.35, 52.77, 58.81, 57.67, 59.56, 52.7]
df_4 = pd.DataFrame({"Silbe": silben, "Silbendauer(ms)": silbendauer, "Grundfrequenz": f0, "Intensitaet(dB)": intensity})
df_4 = df_4.set_index("Silbe")
df_4["Silbendauer(%)"] = df_4["Silbendauer(ms)"] / df_4["Silbendauer(ms)"].sum() *100
df_4
| Silbendauer(ms) | Grundfrequenz | Intensitaet(dB) | Silbendauer(%) | |
|---|---|---|---|---|
| Silbe | ||||
| Der | 0.116 | 106.00 | 54.35 | 10.375671 |
| Stu | 0.153 | NaN | 52.77 | 13.685152 |
| dent | 0.269 | 109.00 | 58.81 | 24.060823 |
| lernt | 0.181 | 118.10 | 57.67 | 16.189624 |
| Ma | 0.174 | 156.30 | 59.56 | 15.563506 |
| the | 0.225 | 99.34 | 52.70 | 20.125224 |
Im Allgemeinen laesst sich auch mit nur einem Pitch-Point noch immer ganz gut erkennen, welche Silben betont sind. Dies liegt vermutlich daran, dass neben dem Pitch auch die Laenge der Silbe und deren Intensitaet Informationen ueber deren Betonung enthalten und diese gehen auch bei einem Signal mit monotonen Pitch nicht verloren.
print("Betontes Wort: Student")
display(df_1)
print("Betontes Wort: lernt")
display(df_2)
print("Betontes Wort: Mathe")
display(df_3)
print("Breite Betonung")
display(df_4)
Betontes Wort: Student
| Silbendauer(ms) | Grundfrequenz | Intensitaet(dB) | Silbendauer(%) | |
|---|---|---|---|---|
| Silbe | ||||
| Der | 0.127 | 113.20 | 66.10 | 8.344284 |
| Stu | 0.221 | 114.60 | 57.00 | 14.520368 |
| dent | 0.391 | 150.40 | 85.90 | 25.689882 |
| lernt | 0.306 | 95.87 | 56.10 | 20.105125 |
| Ma | 0.167 | 102.60 | 58.20 | 10.972405 |
| the | 0.310 | 98.63 | 54.34 | 20.367937 |
Betontes Wort: lernt
| Silbendauer(ms) | Grundfrequenz | Intensitaet(dB) | Silbendauer(%) | |
|---|---|---|---|---|
| Silbe | ||||
| Der | 0.140 | 105.50 | 53.4 | 8.900191 |
| Stu | 0.198 | NaN | 53.4 | 12.587413 |
| dent | 0.307 | 110.20 | 52.1 | 19.516847 |
| lernt | 0.422 | 135.40 | 66.1 | 26.827718 |
| Ma | 0.258 | 132.80 | 59.7 | 16.401780 |
| the | 0.248 | 99.15 | 53.2 | 15.766052 |
Betontes Wort: Mathe
| Silbendauer(ms) | Grundfrequenz | Intensitaet(dB) | Silbendauer(%) | |
|---|---|---|---|---|
| Silbe | ||||
| Der | 0.132 | 111.9 | 54.81 | 10.526316 |
| Stu | 0.191 | 121.4 | 54.37 | 15.231260 |
| dent | 0.282 | 105.1 | 51.42 | 22.488038 |
| lernt | 0.231 | 120.0 | 52.28 | 18.421053 |
| Ma | 0.194 | 132.8 | 63.17 | 15.470494 |
| the | 0.224 | 106.0 | 56.69 | 17.862839 |
Breite Betonung
| Silbendauer(ms) | Grundfrequenz | Intensitaet(dB) | Silbendauer(%) | |
|---|---|---|---|---|
| Silbe | ||||
| Der | 0.116 | 106.00 | 54.35 | 10.375671 |
| Stu | 0.153 | NaN | 52.77 | 13.685152 |
| dent | 0.269 | 109.00 | 58.81 | 24.060823 |
| lernt | 0.181 | 118.10 | 57.67 | 16.189624 |
| Ma | 0.174 | 156.30 | 59.56 | 15.563506 |
| the | 0.225 | 99.34 | 52.70 | 20.125224 |
Wir haben uns entschieden die Silbendauer ebenfalls in % zur Gesamtlaenge darzustellen, um eine bessere Vergleichsgrundlage zu schaffen. Damit ist dann auch recht eindeutig geworden, dass die betonten Woerter im Schnitt laenger und lauter als die Unbetonten sind und eine hoehere Grundfrequenz aufweisen. Also lauter sind.
Audio('sound/4_slowed.wav')
Wir haben den 4. Satz auf das 1.6 fache verlangsamt. Beim Verlangsamen nimmt die Tonqualitaet ab, da die neuen Punkte zwischen den urspruenglichen Tonpunkten interpoliert werden. Diese Interpolation schafft es nicht, ein natuerlich klingendes Signal zu erschffen.
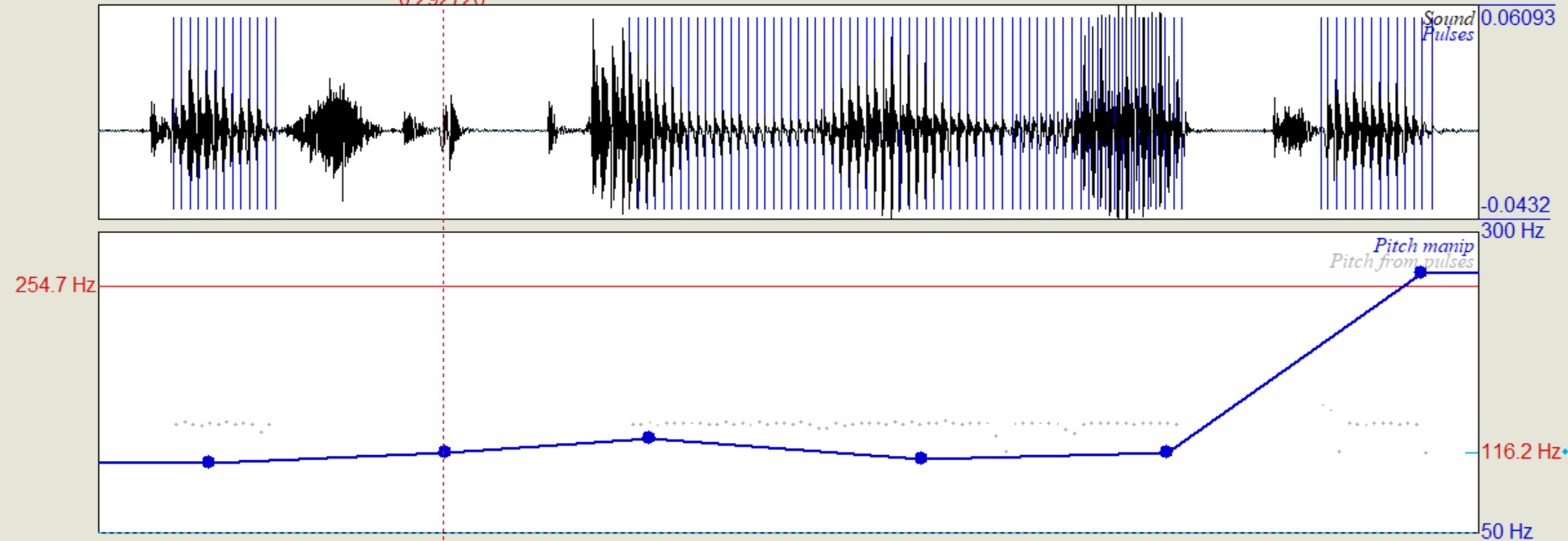
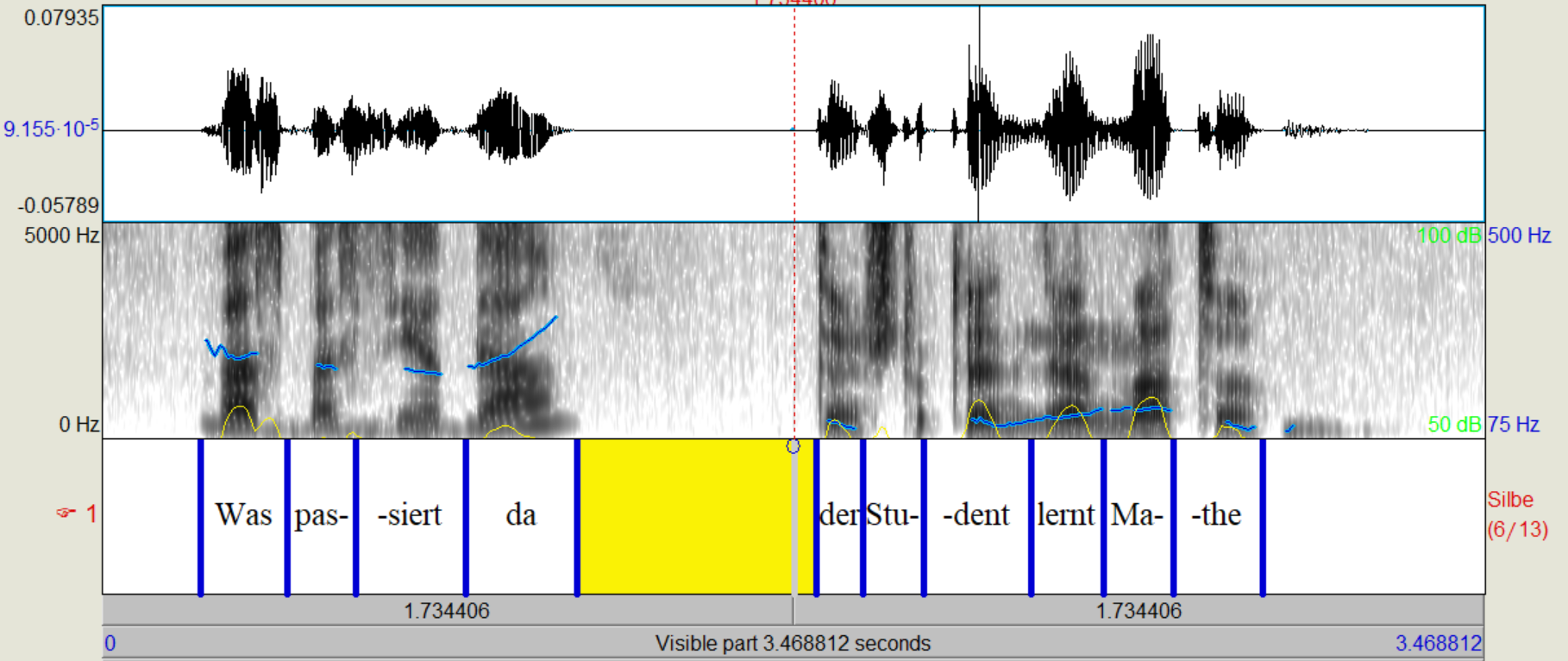
Wir haben "Der Student lernt Mathe?" als Frage aufgenommen und mit dem letzten Staz(breiter Fokus) verglichen. Dabei ist der eindeutigste Unterschied, dass im letzten Wort ("Mathe") die Intensitaet deutlich hoeher ist und das die Grundfrequenz zum Ende hin stark ansteigt.
Audio('sound/frage.wav')
Audio('sound/aussage.wav')
Audio('sound/4_frage_synth.wav')
Daraufhin haben wir zu der oben generierten monotonen Version der Aussage weitere Pitch-Points zugefuegt. Die Werte von diesen sind aus der aufgenommenen Frage genommen. Das dadurch generierte Signal klingt durchaus wieder wie eine Frage.